10. SOAPSonar – Distributing Load Testing Geographically
Physically distributing the location of load test clients has 2 benefits. Firstly, it overcomes the limitations of network segment and works station resources. Secondly it allows for the testing and understanding of the impact of network and location on load and performance.
Yes, you could run around, call different people and press the button at the same time, but integrating the test results can then be very difficult. Triggering a load test from a single central instance, across multiple physical machines, and centralizing the report generates a single drill down report.
In my previous tutorial we load tested using 3 virtual machines, using only one physical machine – SOAPSonar. This tutorial carries on were that one ended, so please do tutorial 9 first if you have not. This tutorial will now distribute the same test across multiple physical machines or “agents”
1. Check to make sure you still running the CloudPort Runtime and Performance Test Tutorial is loaded. this will be the service we will load test against. Confirm the IP address and URI.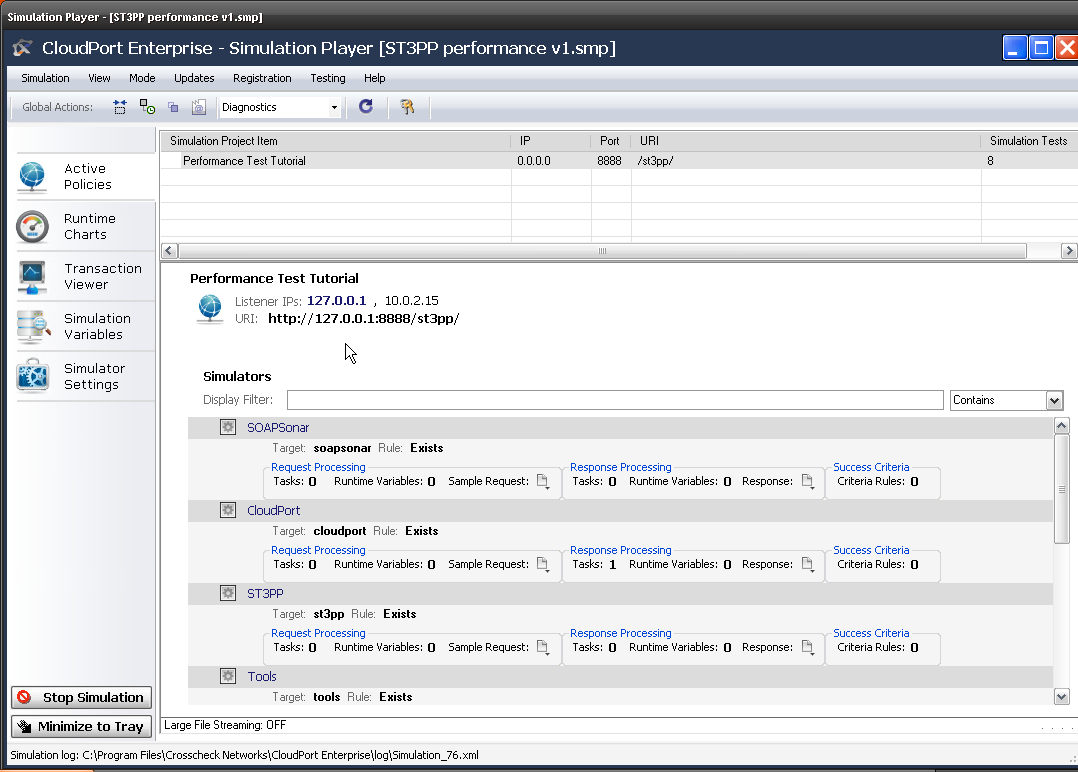
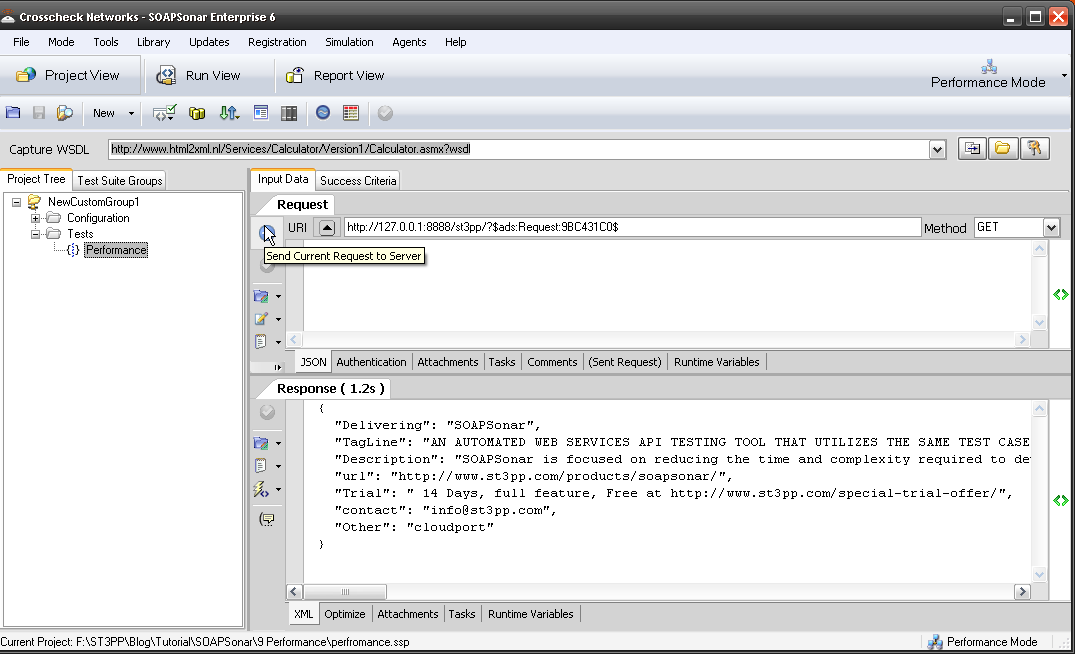
2. Launch SOAPSonar and go back into Project view and just run a quick Send request to server to make sure it is all working still. This confirm your [ADS] is in place and your runtime is up and URI is right.
3. Now we need to download our Physical Agent client software. Select Agents in the Top menu (next to help) then Download SOASPSonar Agent Installer. Your browser should launch and you should be able to download the latest agent by selecting it. Its important to keep your SOAPSonar Release and the Agent on the same release. Install the agent on your own machine or another if you would prefer.
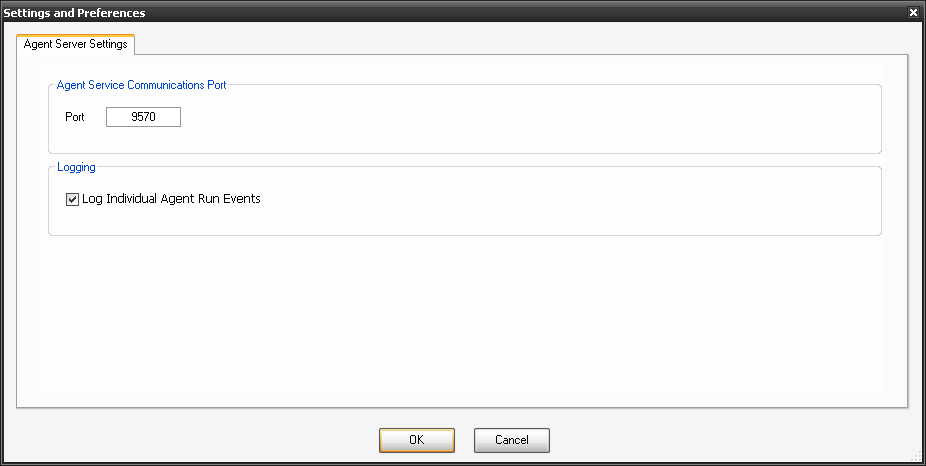
4. Run the agent software after installation and select File, Preferences.
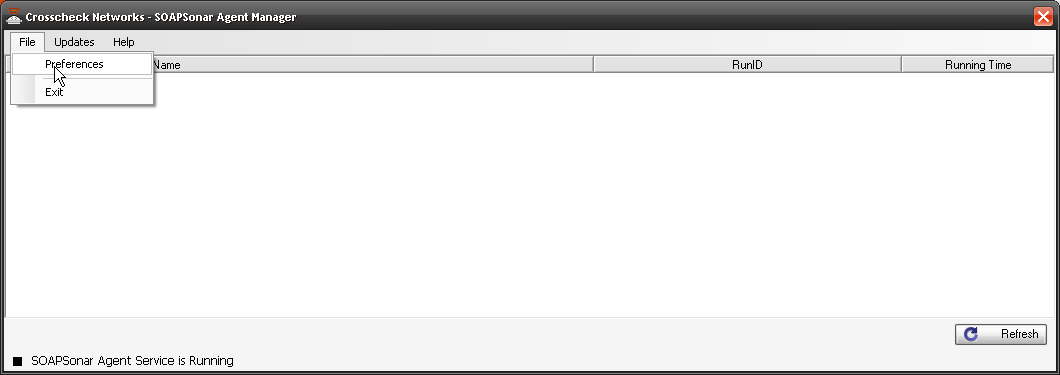
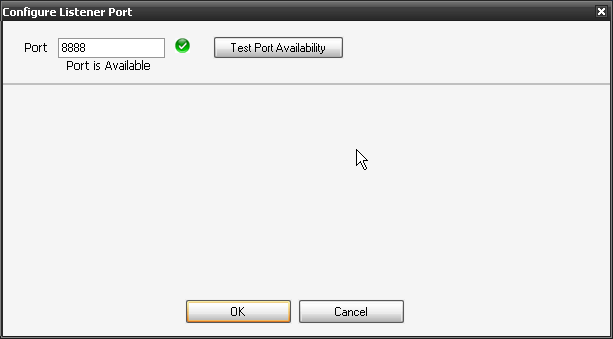
5. Confirm your port and Select Log Individual Agent Run Events. You should now see CloudPort and Agent in your task bar.
![]()
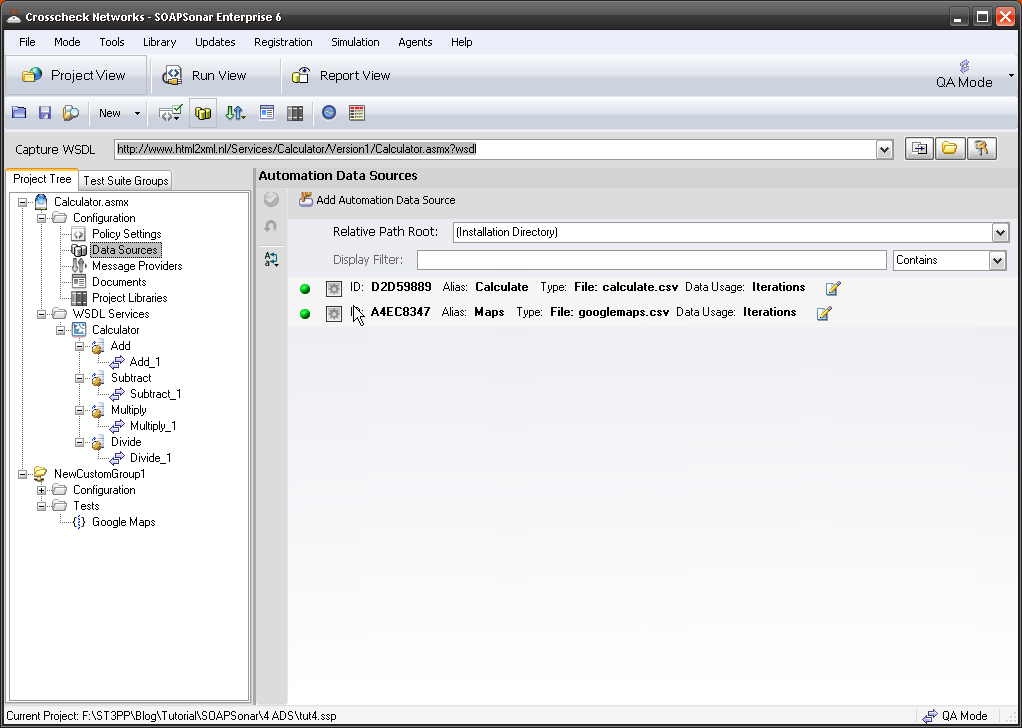
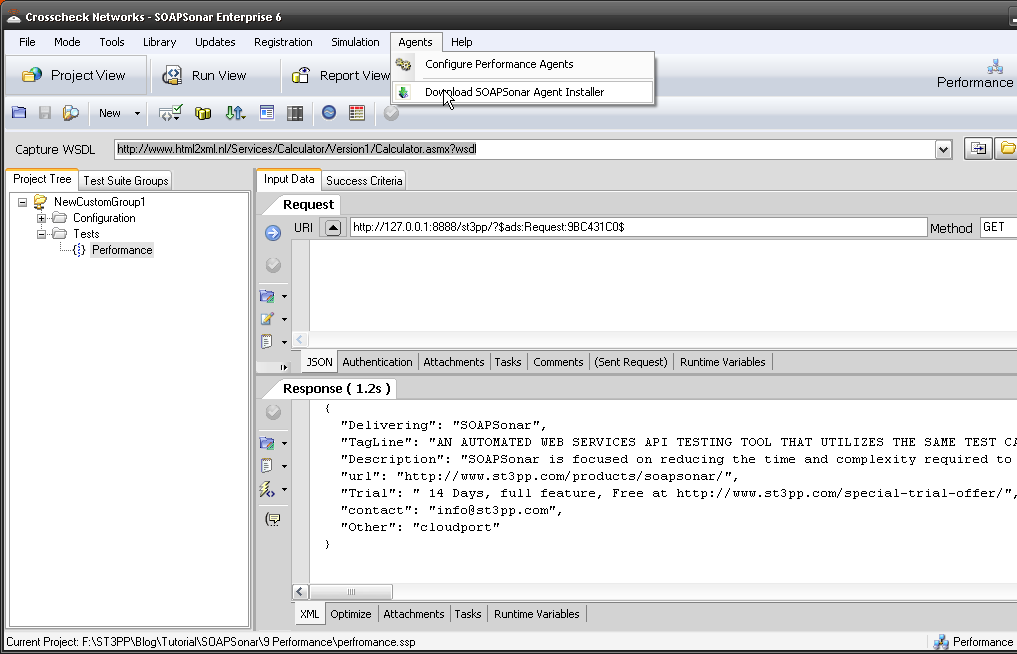
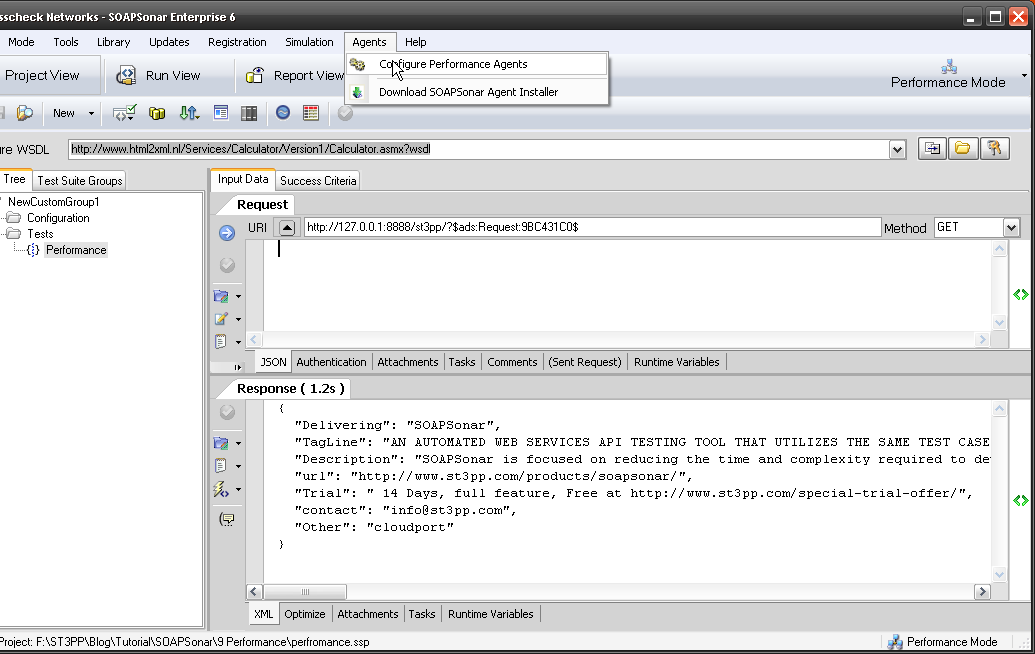
6. Now we need to tell SOAPSonar that we have a agent available. In SOAPSonar select Configure, Agents.
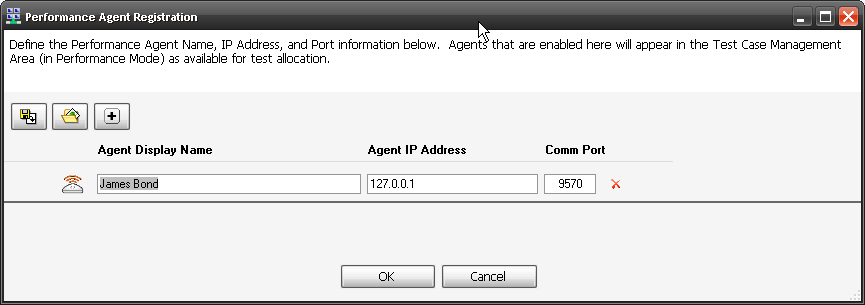
7. Select the Icon for add a New Agent, Give it a name that so you remember were it is. (like Montreal, Vancouver, Halifax, London or in my case James Bond). Then the IP address of the Agent (in my case its local so 127.0.0.1) and confirm the same port we checked in 5 above. Select OK. We now have a Agent to use along with our local instance in load tests. The idea is not to have it on the same machine for load tests, and preferably on a different network segment, but this is just a tutorial on how.
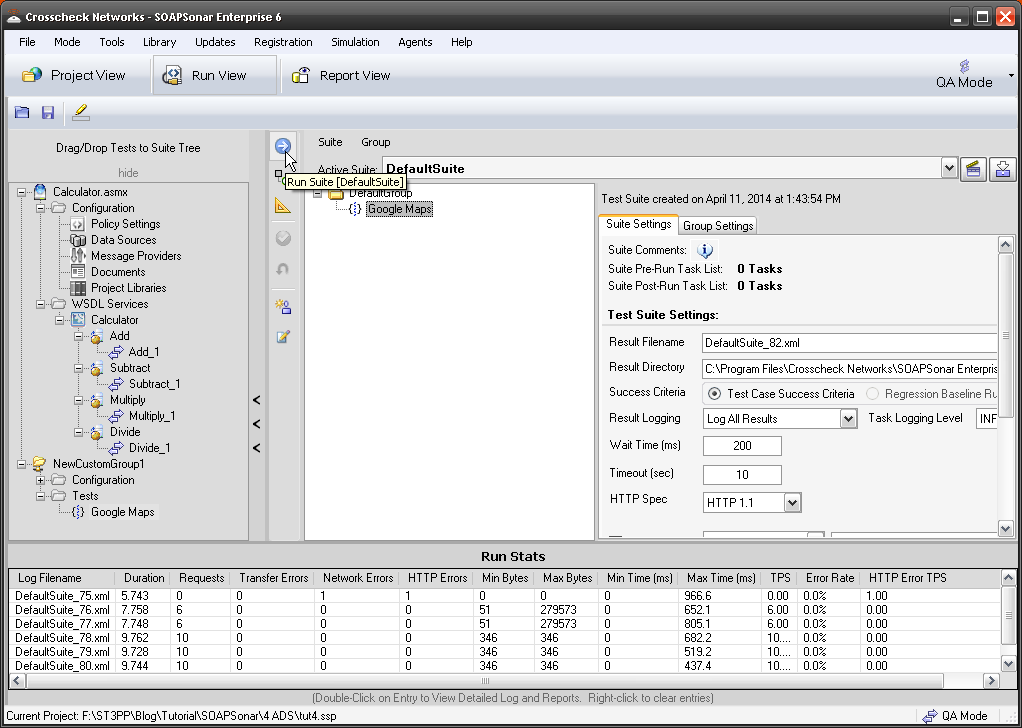
8. Now switch to Run View, and we should still have the same DefaultGroup and Group Performance Settings from the previous tutorial. Select Performance Loading Agents. Select Import Default Agent Definitions icon and your agent should be shown. Activate it by selecting the Red dot to Green. Commit settings to save your agent.
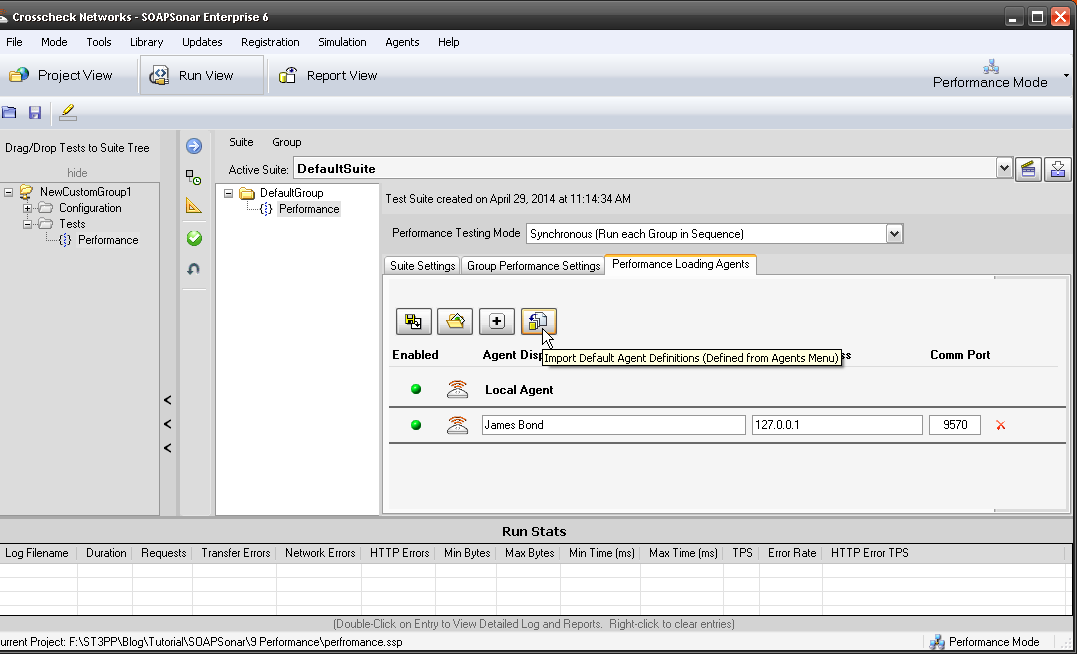
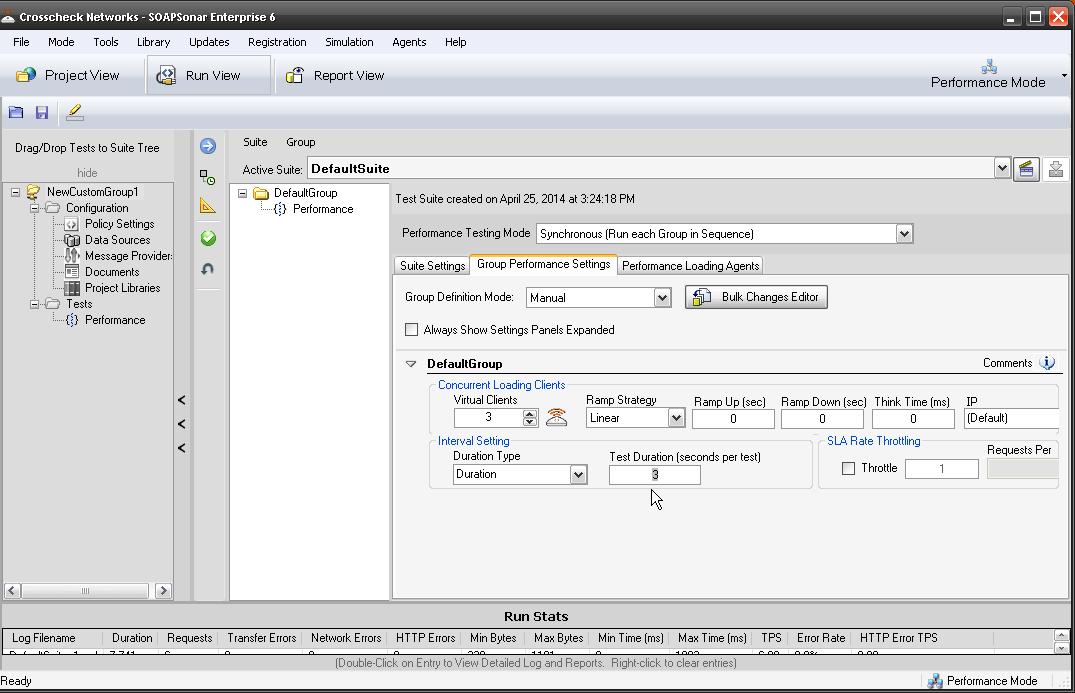
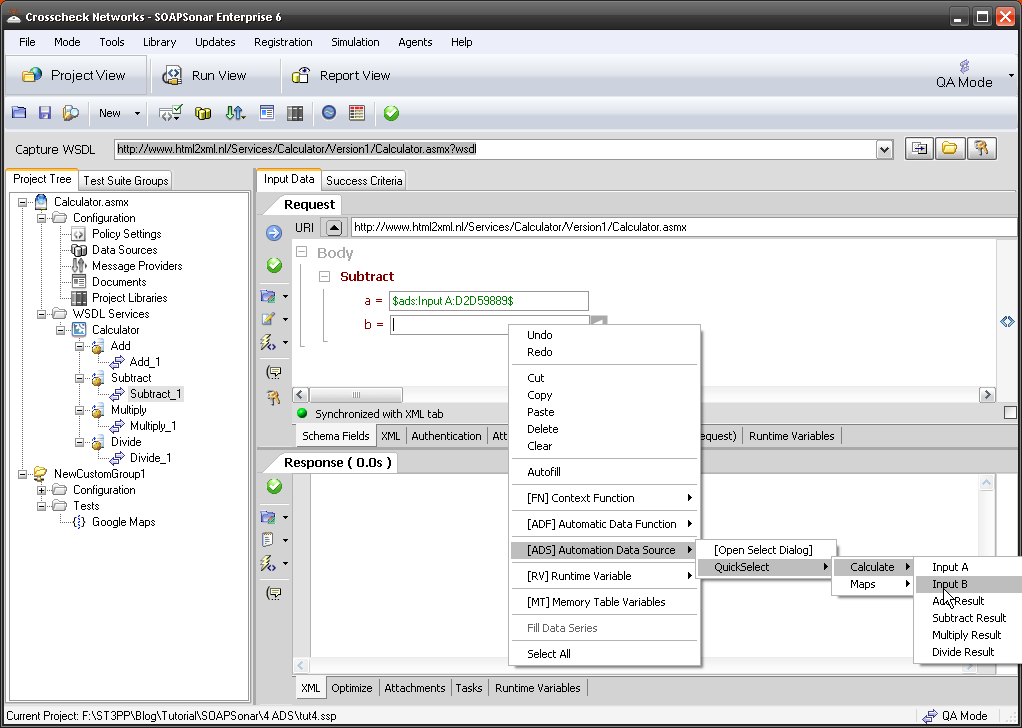
9. Now all we have to do is allocate how many virtual users to each agent. You have both your local SOAPSonar instance or Local Agent and then the new one we created. Select Group Performance Settings and change the Virtual Clients to 4. Then right next to that, select the icon for Agent Thread Allocation.
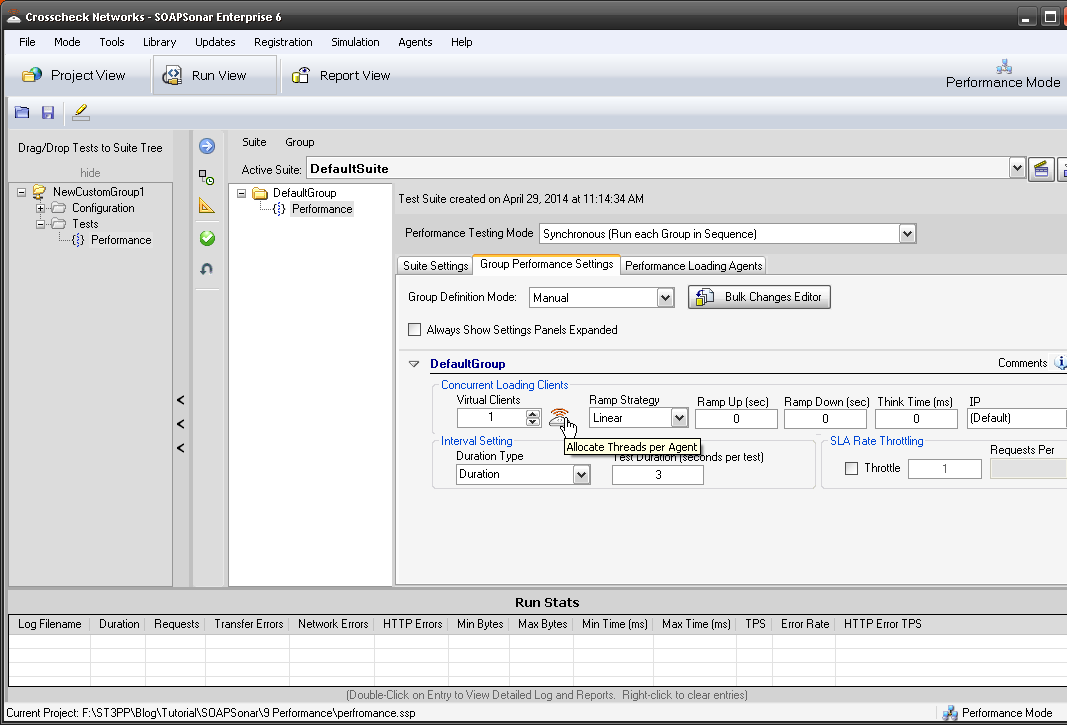
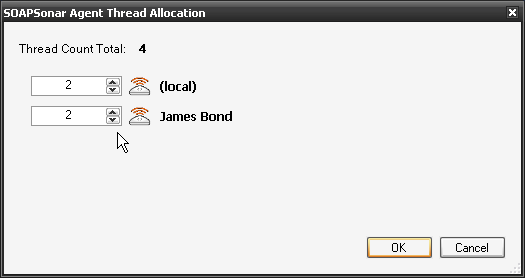
10. Lets give 2 Virtual Agents to each of or physical agents. Confirm duration is 3 seconds and Commit and Run Suite.
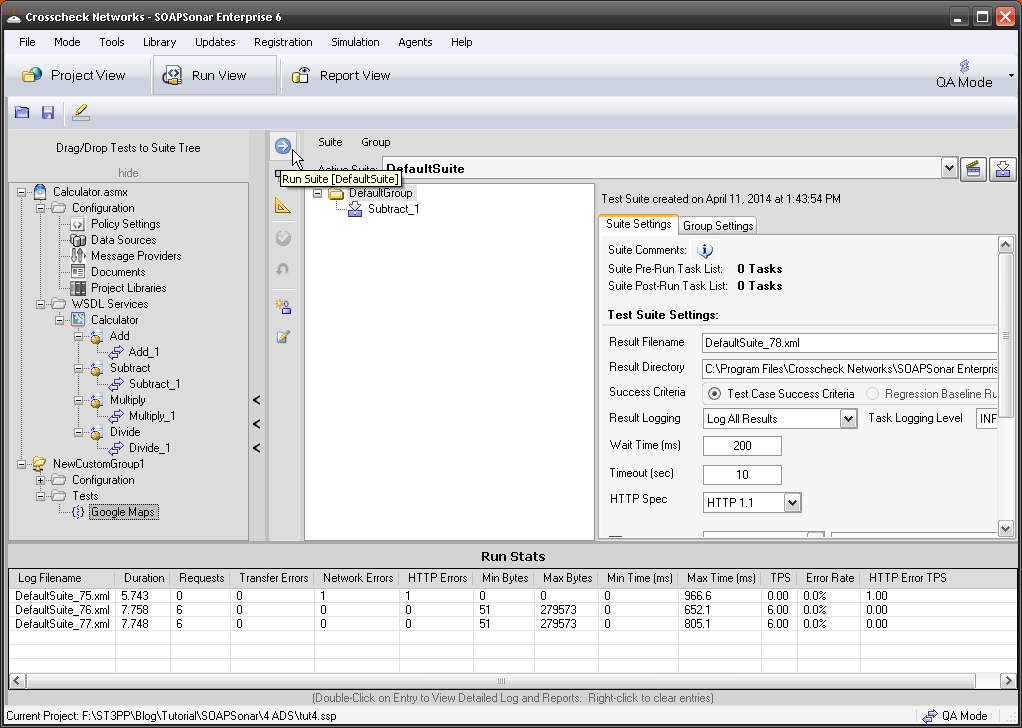
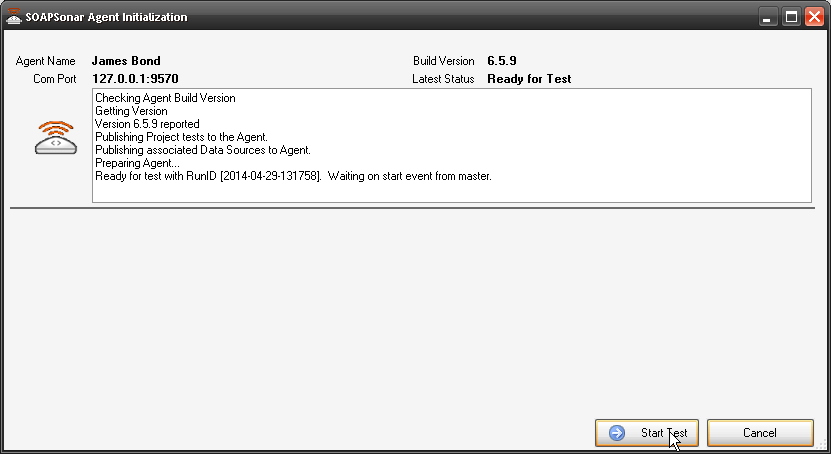
11. You should now see the Agent Initialization Screen. Once the agent is initialized, select Start Test. If your agent does not initialize, check the IP address and Port and ensure you can ping the agent.
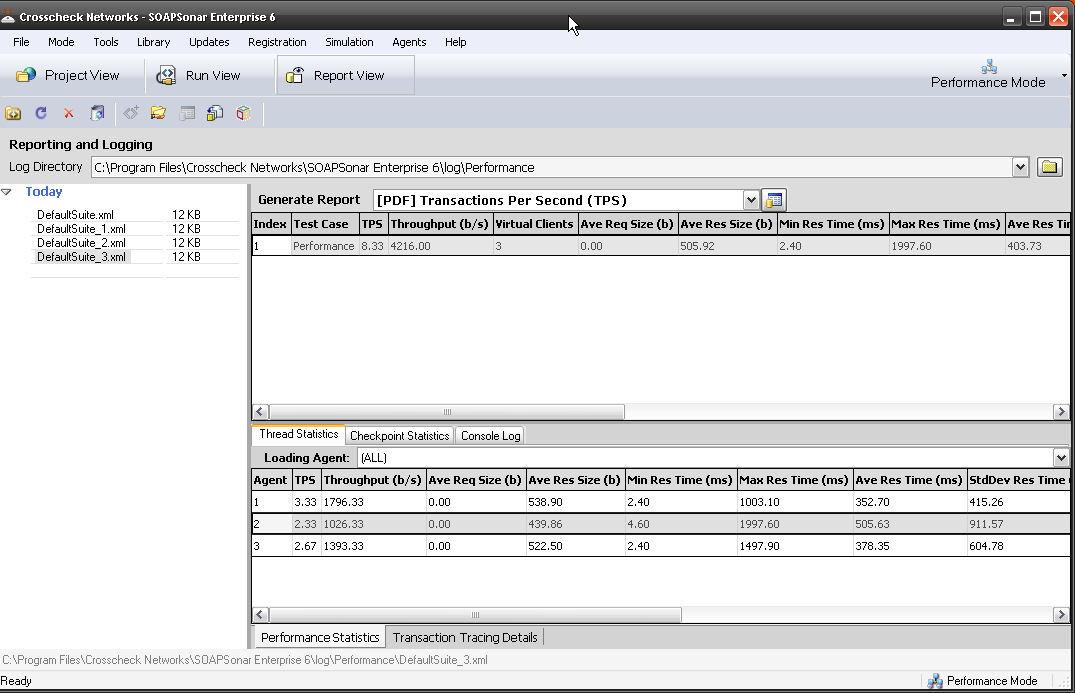
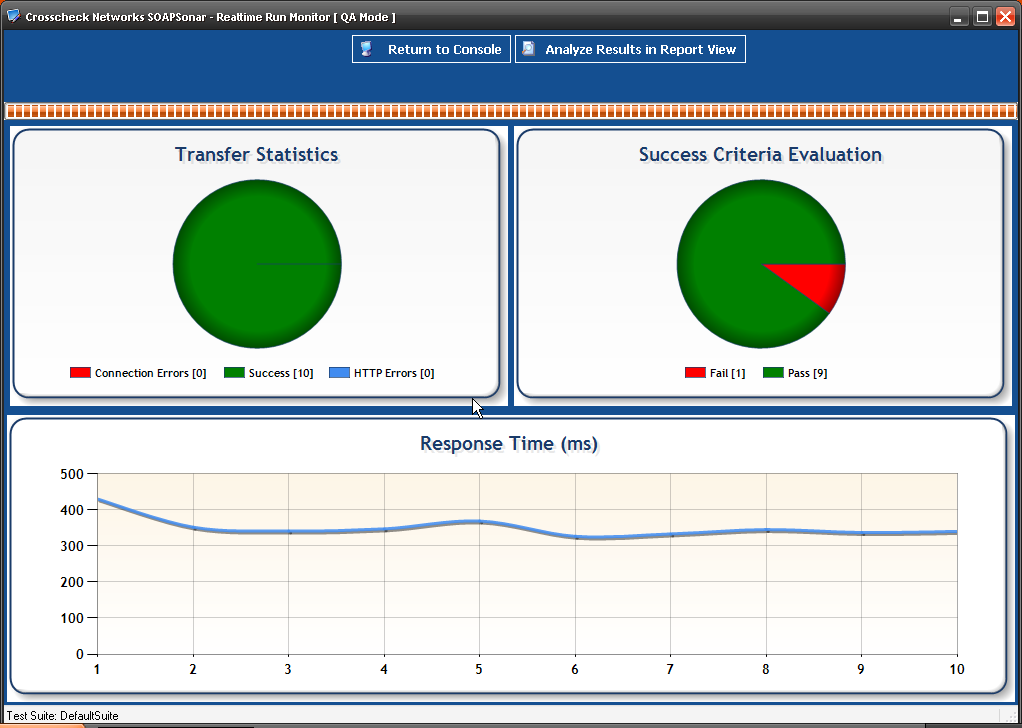
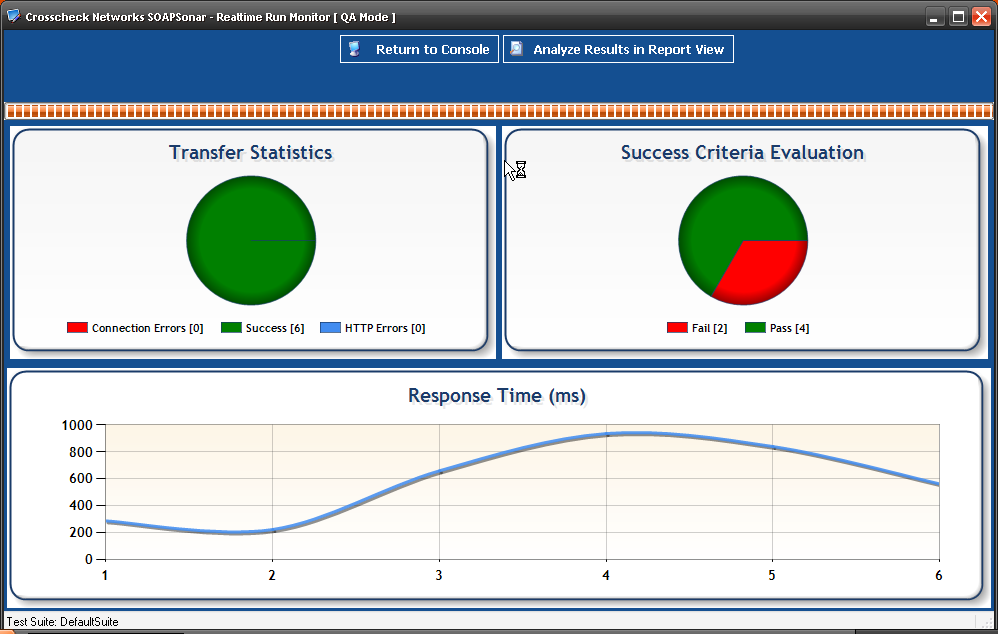
12 In the Real-Time Monitor, you see you can now view performance by physical agent.
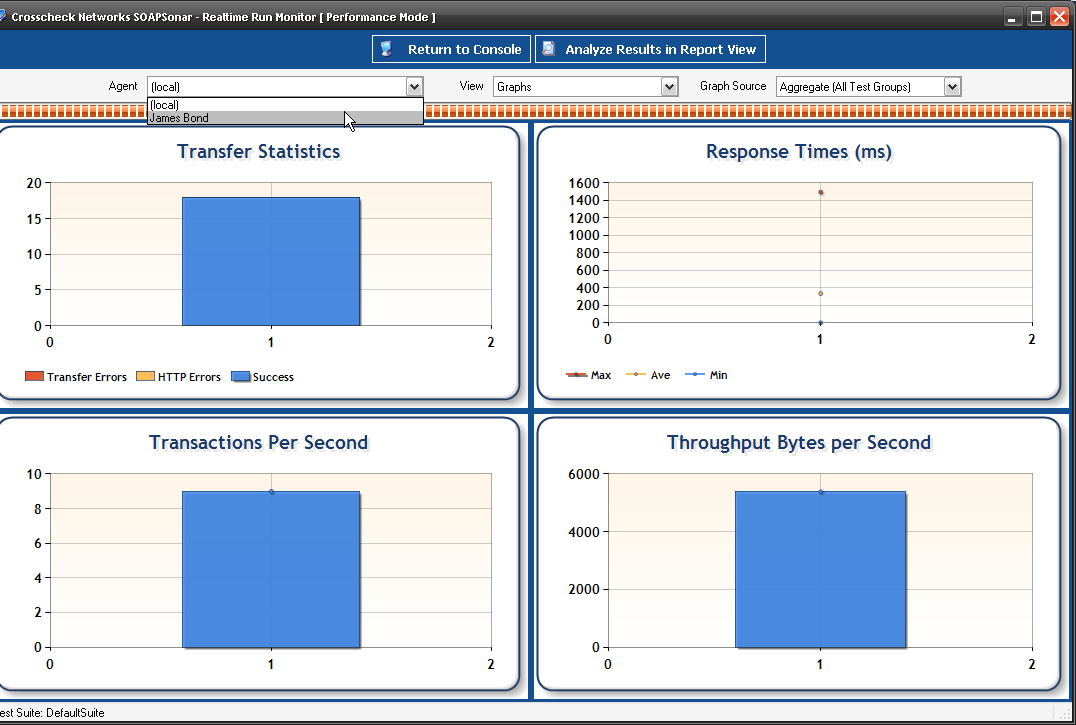
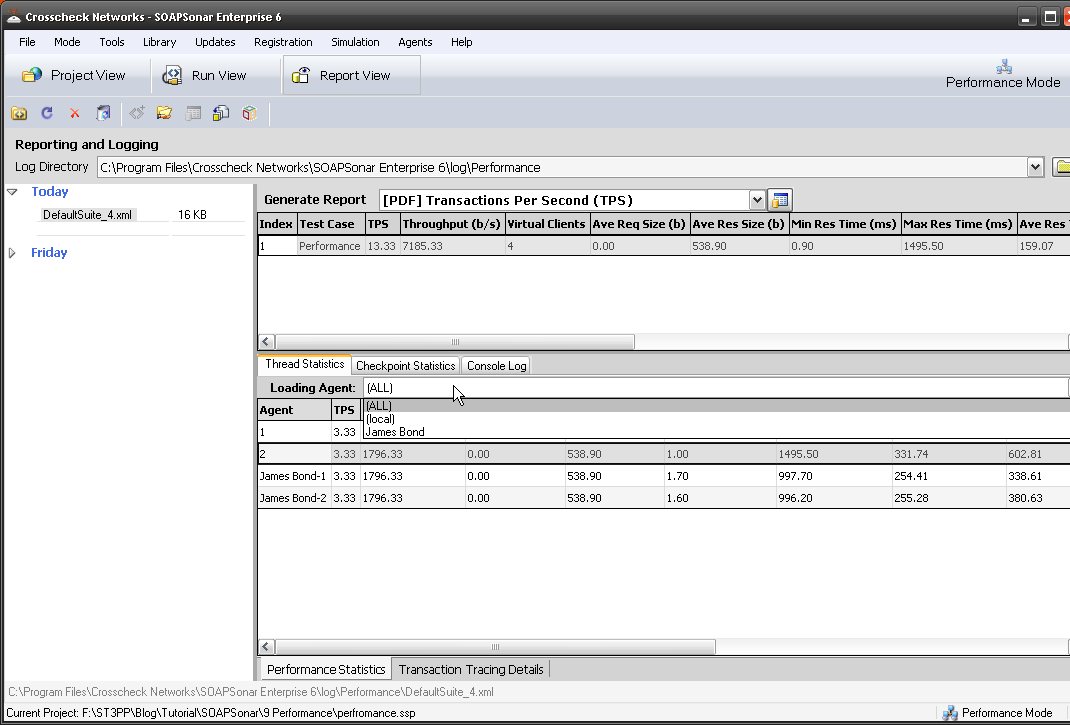
13. In Report View, you can now show performance for one Physical Agent, One Virtual Agent or aggregated. This allows to to compare performance from one physical location to another.
Conclusion
Distributed agents is part of the Server Edition of SOAPSonar, along with expanded number of virtual users. Physical Load agents allows performance testing to scale through distributing the agents and resources. It also allows for testing of network infrastructure as well and application performance. Using the same Test Suite again as we use for functional testing, regression and performance to save time and be easily automated.
This is the end of the introductory series of Tutorials. If you doing a trial and just looking for a high level understanding how SOAPSonar can help you, you should be on your way. From time to time I will post new tutorials on new features, different options and greater challenges. Other features not as of yet used.
In the mean time, let us know how you enjoyed these. Private comment in the form below and public by starting a discussion at the bottom of the page.
Warning: strpos() expects parameter 1 to be string, array given in /home/content/13/11164213/html/ST3PP/wp-includes/shortcodes.php on line 193
[contact-form to=’[email protected]’ subject=’I just completed SOAPSonar Tutorial 10′][contact-field label=’Name what you want to be called.’ type=’name’ required=’1’/][contact-field label=’Email if you want a response.’ type=’email’/][contact-field label=’Comment. ‘ type=’textarea’/][/contact-form]
Comment or suggestions always welcome.